


SimpleQA is ontwikkeld door AI-onderzoekers om het vermogen van taalmodellen te beoordelen bij het beantwoorden van vragen, gebaseerd op gegevens van chatbots zoals ChatGPT, Gemini en Claude. Deze beoordelingsschaal biedt gebruikers informatie om de meest nauwkeurige chatbot-tool te kiezen.
1. Wat is SimpleQA?
SimpleQA (Simple Question Answering) is een nieuwe beoordelingsstandaard die is ontworpen om de nauwkeurigheid van AI-modellen bij het beantwoorden van korte vragen te meten. In tegenstelling tot oudere standaarden zoals TriviaQA (2017) of Natural Questions – NQ (2019), richt SimpleQA zich op het beoordelen van de realiteitswaarde van antwoorden, waardoor AI-experts AI-hallucinaties kunnen identificeren en verminderen.
SimpleQA is bijzonder belangrijk nu steeds meer grote technologiebedrijven zoals OpenAI, Google DeepMind en Meta AI streven naar slimmere en nauwkeurigere AI. Onder deze modellen wordt GPT-4.5 hoog gewaardeerd binnen de productgeneraties van OpenAI.
Wat maakt SimpleQA bijzonder?
- Hoge nauwkeurigheid: Elke vraag heeft slechts één correct antwoord, geverifieerd door twee onafhankelijke experts.
- Uitdagend niveau: De vragen in SimpleQA zijn moeilijker dan oudere datasets, waardoor zelfs GPT-4o slechts minder dan 40% scoorde tijdens tests.
- Betrouwbaarheidsbeoordeling van AI: SimpleQA meet niet alleen nauwkeurigheid, maar controleert ook of AI zich bewust is van zijn eigen onzekerheden.
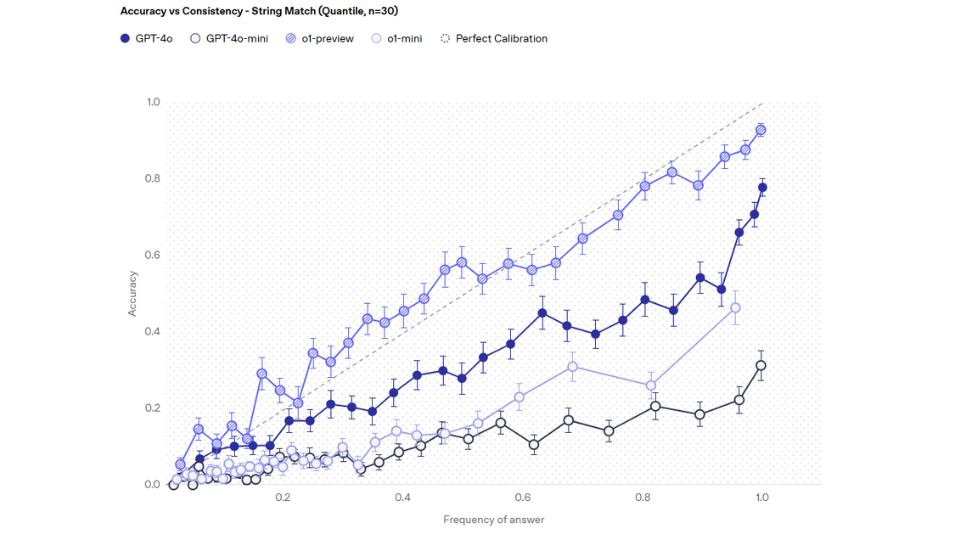
2. De beoordelingsmethode van Simple Question Answering
SimpleQA is opgebouwd volgens een strikt validatieproces dat uit drie hoofdfasen bestaat: het opstellen van vragen, het verifiëren van antwoorden en de kwaliteitscontrole. Alle methoden en processen van SimpleQA zijn gebaseerd op betrouwbare gegevens voor een objectieve beoordeling.
2.1. Het opstellen van de vragen
- AI-experts verzamelen en formuleren 4.326 korte vragen op basis van betrouwbare informatiebronnen.
- Elke vraag is ontworpen om slechts één correct antwoord te hebben, zonder alternatieve interpretaties.
- De onderwerpen bestrijken verschillende domeinen zoals wetenschap, geschiedenis, technologie, cultuur en geografie, om AI-modellen niet te beperken tot één specifiek onderwerp.
2.2. Het verifiëren van antwoorden
- Twee onafhankelijke experts geven antwoorden op elke vraag.
- Als beide experts hetzelfde antwoord geven, wordt de vraag opgenomen in de dataset.
- Bij discrepanties wordt de vraag verwijderd of aangepast.
2.3. Kwaliteitscontrole
- Een derde expert controleert willekeurig 1.000 vragen, met de volgende resultaten:
- 94,4% van de vragen was zeer nauwkeurig.
- 5,6% vertoonde lichte verschillen in formulering.
- Na handmatige controle bleek de werkelijke foutmarge van Simple Question Answering slechts ongeveer 3% te zijn.
3. Testresultaten van AI-modellen met SimpleQA
Top-AI-modellen zijn geëvalueerd met de SimpleQA-dataset, en de resultaten tonen duidelijke verschillen in nauwkeurigheid tussen de versies van ChatGPT. Simple Question Answering beoordeelt niet alleen de juiste antwoorden, maar ook de betrouwbaarheid van AI bij complexe vragen.
GPT-4.5 behaalde de hoogste nauwkeurigheidsscore met 62,5%, beter dan GPT-4o (38,2%), OpenAI o1 (47%) en OpenAI o3-mini (15%). Dit toont aan dat grotere modellen beter zijn in informatieopvraging.
GPT-4.5 had het laagste hallucinatiepercentage met 37,1%, terwijl GPT-4o (61,8%), OpenAI o1 (44%) en OpenAI o3-mini (80,3%) aanzienlijk hogere hallucinatiepercentages hadden. Kleinere modellen genereren gemakkelijker misleidende informatie, wat de betrouwbaarheid van AI vermindert.
GPT-4.5 bleek het meest optimale model te zijn, met zowel hoge nauwkeurigheid als minder misinformatie. Daarentegen presteerde GPT-4o aanzienlijk slechter, terwijl OpenAI o1 en o3-mini ondermaats presteerden, wat hun bruikbaarheid in de praktijk beïnvloedde.
De resultaten van Simple Question Answering tonen aan dat grotere AI-modellen, zoals GPT-4.5 en GPT-4o, vaker weigeren antwoord te geven op moeilijke vragen, wat een positief signaal is omdat dit aangeeft dat ze hun eigen betrouwbaarheid beter kunnen inschatten. Kleinere modellen zoals OpenAI o1 en o3-mini daarentegen beantwoorden vragen zelfs wanneer ze onzeker zijn, waardoor het risico op misleidende informatie toeneemt.
4. De impact van SimpleQA op AI en toekomstige technologie
SimpleQA helpt niet alleen bij het beoordelen van AI, maar speelt ook een cruciale rol bij het verbeteren van nauwkeurigheid, het verminderen van AI-hallucinaties en het verhogen van de betrouwbaarheid van modellen in verschillende domeinen.
4.1. Verbetering van AI in informatiezoekopdrachten
Tools zoals Perplexity AI, Google SGE en Bing AI kunnen SimpleQA gebruiken om de nauwkeurigheid te controleren voordat informatie aan gebruikers wordt verstrekt. Een groot probleem in AI is hallucinatie, met foutenmarges variërend van 10% tot 30% (Stanford AI Index 2024). SimpleQA helpt deze marges te detecteren en te verlagen, waardoor AI betrouwbaarder wordt.
4.2. Vermindering van misinformatie
AI kan onbedoeld misinformatie verspreiden, vooral op platforms zoals Facebook, Twitter (X) en YouTube. Bedrijven zoals OpenAI, Google DeepMind en Anthropic gebruiken evaluatietools zoals SimpleQA om het foutpercentage van AI-antwoorden te verlagen van 15% naar minder dan 5%. Dit helpt gebruikers te beschermen tegen onjuiste of misleidende informatie.
4.3. Verbetering van AI in de gezondheidszorg en het onderwijs
- In de gezondheidszorg: Medische chatbots zoals Google Med-PaLM en IBM Watson Health moeten nauwkeurige informatie garanderen. Onderzoek van Harvard Medical School (2023) toont aan dat Simple Question Answering het AI-diagnosefoutpercentage van 18% naar 7% kan verlagen.
- In het onderwijs: AI-ondersteunde leerplatforms zoals Khan Academy en Duolingo kunnen fouten maken bij het uitleggen van concepten. Volgens een UNESCO-rapport (2024) vinden 87% van de docenten AI nuttig, maar 60% maken zich zorgen over de nauwkeurigheid. SimpleQA helpt educatieve AI om gedetailleerdere en nauwkeurigere uitleg te geven.
SimpleQA is een essentiële standaard voor het beoordelen en verbeteren van AI, vooral bij het beperken van AI-hallucinaties en het verhogen van de nauwkeurigheid bij real-world vraagstellingen. Vroege studies tonen aan dat zelfs geavanceerde AI-modellen zoals GPT-4o minder dan 40% nauwkeurigheid behalen, wat een grote uitdaging vormt voor de toekomst van AI.
Voor meer informatie over SimpleQA-geclassificeerde GPT-4.5, het geavanceerde taalmodel met uitstekende nauwkeurigheid, bekijk GPT-4.5 nieuwste klassieke modellijn